


概述
OptiHummingbird®
OptiHummingbird®是首款基于片上光网络技术(oNOC)的全长、全高、双插槽PCIe Gen3的人工智能推理卡,含有64个计算核,结合曦智科技自研SDK,OptiHummingbird®可对工作负载编译和硬件接口进行管理和优化。产品使用被动散热解决方案,硬件功耗仅65w,具有高带宽、低延时、低功耗的特点。




核心技术
片上光网络
曦智科技的片上光网络(oNOC)技术利用光波导替代铜导线进行电芯片内部或者小芯粒之间的数据互连,降低系统延迟,提高整体计算效率。由于光传输对距离不敏感,芯片内部的光网络可以实现低延迟、低功耗的长距离传输。如下图所示,片上光网络可扩展至晶圆级,从而支持数十个电子芯片实现2D环互连或其他类型的各向同性互连网络拓扑结构。

电芯片通过光波导互连形成的晶圆级光网络俯视图
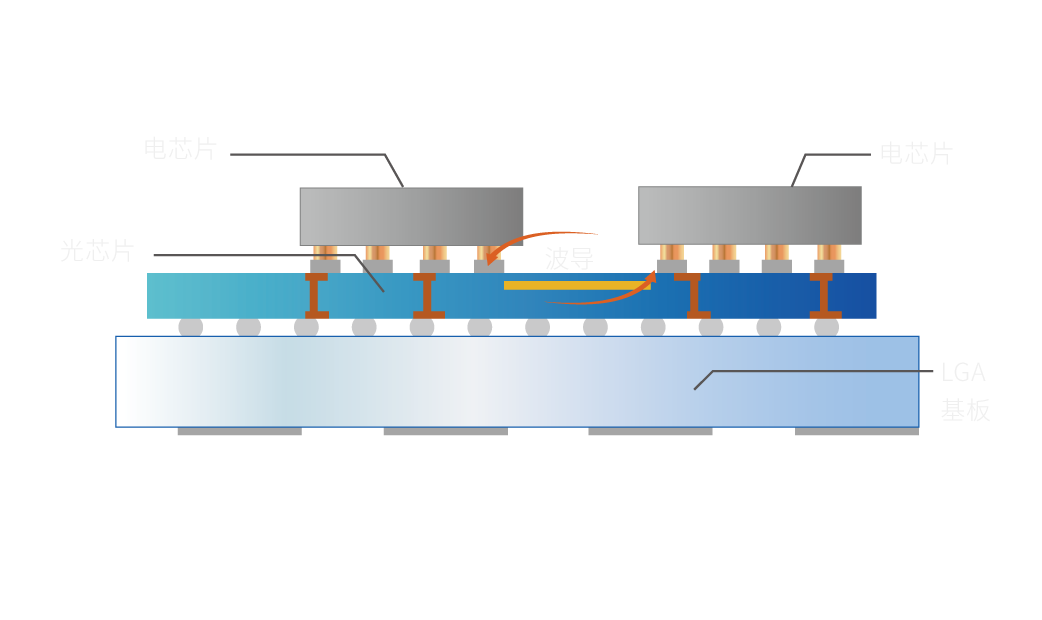
电芯片通过光波导互连的截面图



应用领域

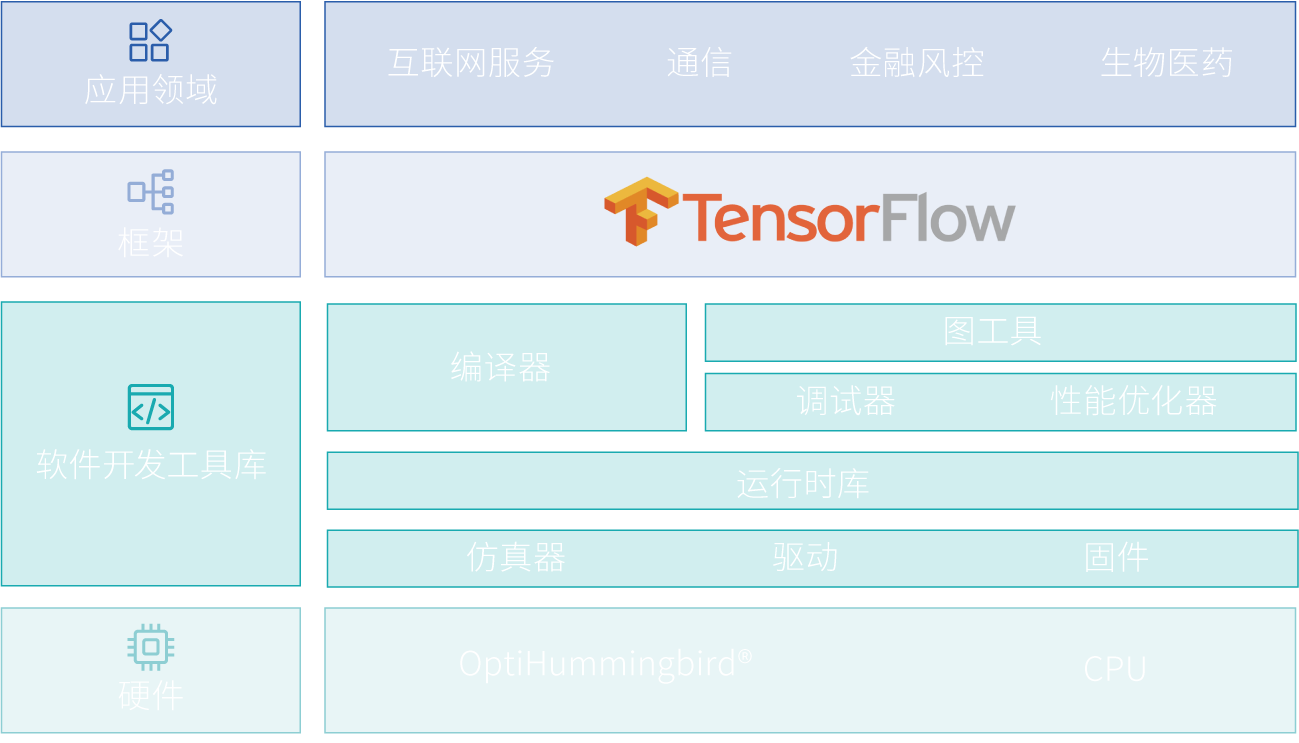
互联网服务

通信

金融风控

生物医药
应用案例
自研软件栈
兼容主流深度学习框架

提供光电混合异构算力平台

兼容TensorFlow深度学习框架

支持图优化和算子融合加速
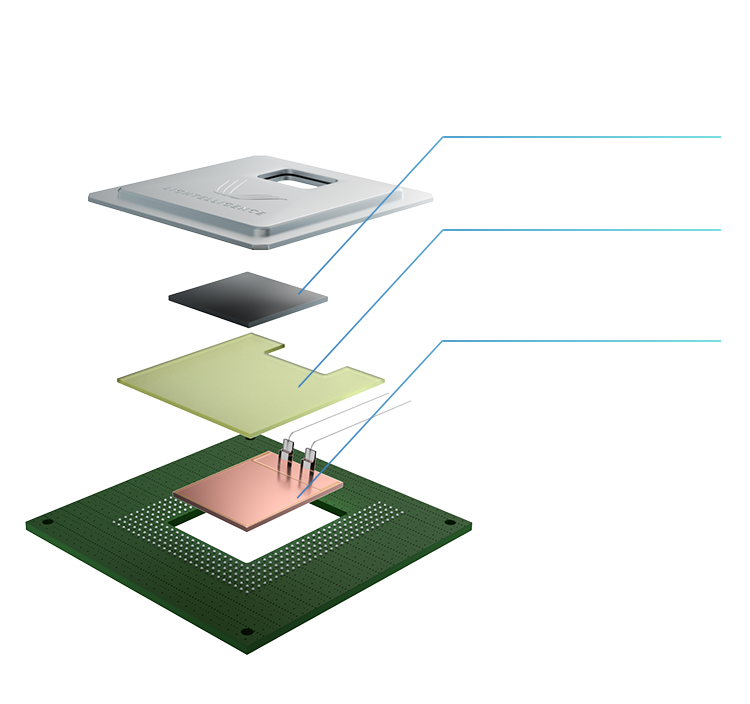
3D封装结构
OptiHummingbird®采用先进垂直堆叠封装技术。通过有机转接板将硅光芯片与电子芯片垂直堆叠在一起,以实现更高的集成度和性能,保证两者无缝协同运作。







电芯片
电芯片的数字部分包括INS/CTL,DPMP,ALU和UMEM等核心组件,模拟部分支撑数模和模数转换
转接板
转接板连接电芯片、光芯片和衬底,支撑数据传输和供电
光芯片
光芯片提供片上数据传输功能,可实现电芯片上64个计算核心的高速全通道广播



Copyright © 2022 曦智科技 沪ICP备2021002597号-1

